
学习 JavaScript 数据结构与算法(第三版)
# 1. 栈数据结构
栈是一种遵从后进先出(LIFO)原则的有序集合。新添加或待删除的元素都保存在栈的同一端,称作栈顶,另一端就叫栈底。在栈里,新元素都靠近栈顶,旧元素都接近栈底。
栈也被用在编程语言的编译器和内存中保存变量、方法调用等,也被用于浏览器历史记录(浏览器的返回按钮)。
class Stack {
constructor() {
this.items = []
}
// 向栈添加元素
push(element) {
this.items.push(element)
}
// 从栈移除元素
pop() {
return this.items.pop()
}
// 查看栈顶元素
peek() {
return this.items[this.items.length - 1]
}
// 检查栈是否为空
isEmpty() {
return this.items.length === 0
}
// 清空栈元素
clear() {
this.items = []
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 2. 用栈解决问题
栈的实际应用非常广泛。在回溯问题中,它可以存储访问过的任务或路径、撤销的操作。
进制转换算法
function baseConverter(decNumber, base) {
const remStack = new Stack()
const digits = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'
let number = decNumber
let rem
let baseString = ''
if (!(base >= 2 && base <= 36)) {
return ''
}
while (number > 0) {
rem = Math.floor(number % base)
remStack.push(rem)
number = Math.floor(number / base)
}
while (!remStack.isEmpty()) {
baseString += digits[remStack.pop()]
}
return baseString
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 3. 队列数据结构
- 队列是遵循先进先出(FIFO,也称为先来先服务)原则的一组有序的项。队列在尾部添加新元素,并从顶部移除元素。最新添加的元素必须排在队列的末尾。
class Queue {
constructor() {
this.count = 0
this.lowestCount = 0
this.items = {}
}
// 向队列添加元素
enqueue(element) {
this.items[this.count] = element
this.count++
}
// 从队列移除元素
dequeue() {
if (this.isEmpty()) {
return undefined
}
const result = this.items[this.lowestCount]
delete this.items[this.lowestCount]
this.lowestCount++
return result
}
// 查看队列头元素
peek() {
if (this.isEmpty()) {
return undefined
}
return this.items[this.lowestCount]
}
// 获取长度
size() {
return this.count - this.lowestCount
}
// 检查队列是否为空
isEmpty() {
return this.size() === 0
}
// 清空队列
clear() {
this.items = {}
this.count = 0
this.lowestCount = 0
}
toString() {
if (this.isEmpty()) {
return ''
}
let objString = `${this.items[this.lowestCount]}`
for (let i = this.lowestCount + 1; i < this.count; i++) {
objString = `${objString},${this.items[i]}`
}
return objString
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 4. 双端队列数据结构
- 双端队列(deque,或称 double-ended queue)是一种允许我们同时从前端和后端添加和移除元素的特殊队列。由于双端队列同时遵守了先进先出和后进先出原则,可以说它是把队列和栈相结合的一种数据结构。
class Deque {
constructor() {
this.count = 0
this.lowestCount = 0
this.items = {}
}
// 向双端队列的前端添加元素
addFront(element) {
if (this.isEmpty()) {
this.addBack(element)
} else if (this.lowestCount > 0) {
this.lowestCount--
this.items[this.lowestCount] = element
} else {
for (let i = this.count; i > 0; i--) {
this.items[i] = this.items[i - 1]
}
this.count++
this.lowestCount = 0
this.items[0] = element
}
}
// 向双端队列的的后端添加元素
addBack(element) {
this.items[this.count] = element
this.count++
}
// 从双端队列的前端移除元素
removeFront() {
if (this.isEmpty()) {
return undefined
}
const result = this.items[this.lowestCount]
delete this.items[this.lowestCount]
this.lowestCount++
return result
}
// 从双端队列的后端移除元素
pop() {
if (this.isEmpty()) {
return undefined
}
this.count--
const result = this.items[this.count]
delete this.items[this.count]
return result
}
// 查看双端队列头元素
peekFront() {
if (this.isEmpty()) {
return undefined
}
return this.items[this.lowestCount]
}
// 查看双端队列尾元素
peekBack() {
if (this.isEmpty()) {
return undefined
}
return this.items[this.count - 1]
}
// 获取长度
size() {
return this.count - this.lowestCount
}
// 检查队列是否为空
isEmpty() {
return this.size() === 0
}
// 清空队列
clear() {
this.items = {}
this.count = 0
this.lowestCount = 0
}
toString() {
if (this.isEmpty()) {
return ''
}
let objString = `${this.items[this.lowestCount]}`
for (let i = this.lowestCount + 1; i < this.count; i++) {
objString = `${objString},${this.items[i]}`
}
return objString
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
# 5. 使用队列和双端队列来解决问题
- 循环队列 —— 击鼓传花游戏。
function hotPotato(elementsList, num) {
const queue = new Queue()
const elimitatedList = []
for (let i = 0; i < elementsList.length; i++) {
queue.enqueue(elementsList[i])
}
while (queue.size() > 1) {
for (let i = 0; i < num; i++) {
queue.enqueue(queue.dequeue())
}
elimitatedList.push(queue.dequeue())
}
return {
eliminated: elimitatedList,
winner: queue.dequeue(),
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 回文检查器。
回文是正反都能读通的单词、词组、数或一系列字符的序列,例如 madam 或 racecar。
function palindromeChecker(aString) {
if (
aString === undefined ||
aString === null ||
(aString !== null && aString.length === 0)
) {
return false
}
const deque = new Deque()
const lowerString = aString
.toLocaleLowerCase()
.split(' ')
.join('')
let isEqual = true
let firstChar, lastChar
for (let i = 0; i < lowerString.length; i++) {
deque.addBack(lowerString.charAt(i))
}
while (deque.size() > 1 && isEqual) {
firstChar = deque.removeFront()
lastChar = deque.removeBack()
if (firstChar !== lastChar) {
isEqual = false
}
}
return isEqual
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 6. 链表数据结构
- 链表存储有序的元素集合,但不同于数组,链表中的元素在内存中并不是连续放置的。每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(也称指针或链接)组成。

function defaultEquals(a, b) {
return a === b
}
class Node {
constructor(element) {
this.element = element
this.next = undefined
}
}
class LinkedList {
constructor(equalsFn = defaultEquals) {
this.count = 0
this.head = undefined
// 比较函数
this.equalsFn = equalsFn
}
// 向链表尾部添加元素
push(element) {
const node = new Node(element)
let current
if (this.head == null) {
this.head = node
} else {
current = this.head
while (current.next != null) {
// 获得最后一项
current = current.next
}
// 将其 next 赋为新元素,建立链接
current.next = node
}
this.count++
}
// 从任意位置移除元素
removeAt(index) {
// 检查越界值
if (index >= 0 && index < this.count) {
let current = this.head
// 移除第一项
if (index === 0) {
this.head = current.next
} else {
const previous = this.getElementAt(index - 1)
current = previous.next
previous.next = current.next
}
this.count--
return current.element
}
return undefined
}
// 循环迭代链表直到目标位置
getElementAt(index) {
if (index >= 0 && index <= this.count) {
let node = this.head
for (let i = 0; i < index && node != null; i++) {
node = node.next
}
return node
}
return undefined
}
// 在任意位置插入元素
insert(element, index) {
if (index >= 0 && index <= this.count) {
const node = new Node(element)
if (index === 0) {
// 在第一个位置添加
const current = this.head
node.next = current
this.head = node
} else {
const previous = this.getElementAt(index - 1)
const current = previous.next
node.next = current
previous.next = node
}
this.count++ // 更新链表的长度
return true
}
return false
}
// indexOf 方法:返回一个元素的位置
indexOf(element) {
let current = this.head
for (let i = 0; i < this.count && current != null; i++) {
if (this.equalsFn(element, current.element)) {
return i
}
current = current.next
}
return -1
}
// 从链表中移除元素
remove(element) {
const index = this.indexOf(element)
return this.removeAt(index)
}
// 检查链表是否为空
isEmpty() {
return this.size() === 0
}
// 获取链表长度
size() {
return this.count
}
// 获取链表头部
getHead() {
return this.head
}
toString() {
if (this.head == null) {
return ''
}
let objString = `${this.head.element}`
let current = this.head.next
for (let i = 1; i < this.size() && current != null; i++) {
objString = `${objString},${current.element}`
current = current.next
}
return objString
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
# 7. 双向链表
- 双向链表和普通链表的区别在于,在链表中,一个节点只有链向下一个节点的链接。而在双向链表中,链接是双向的:一个链向下一个元素,另一个链向前一个元素。
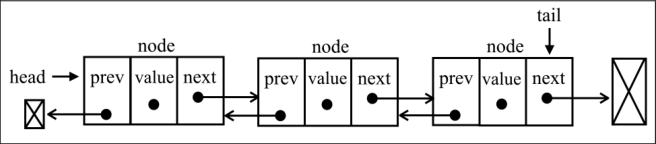
class DoublyNode extends Node {
constructor(element, next, prev) {
super(element, next)
this.prev = prev // 新增的
}
}
class DoublyLinkedList extends LinkedList {
constructor(equalsFn = defaultEquals) {
super(equalsFn)
this.tail = undefined // 新增的
}
// 在任意位置插入新元素
insert(element, index) {
if (index >= 0 && index <= this.count) {
const node = new DoublyNode(element)
let current = this.head
if (index === 0) {
// 新增的
if (this.head == null) {
this.head = node
this.tail = node
} else {
node.next = this.head
current.prev = node // 新增的
this.head = node
}
// 最后一项 // 新增的
} else if (index === this.count) {
current = this.tail
current.next = node
node.prev = current
this.tail = node
} else {
const previous = this.getElementAt(index - 1) // {9}
current = previous.next
node.next = current
previous.next = node
current.prev = node // 新增的
node.prev = previous // 新增的
}
this.count++
return true
}
return false
}
// 从任意位置移除元素
removeAt(index) {
if (index >= 0 && index < this.count) {
let current = this.head
if (index === 0) {
this.head = current.next
// 如果只有一项,更新 tail // 新增的
if (this.count === 1) {
this.tail = undefined
} else {
this.head.prev = undefined
}
// 最后一项 //新增的
} else if (index === this.count - 1) {
current = this.tail
this.tail = current.prev
this.tail.next = undefined
} else {
current = this.getElementAt(index)
const previous = current.prev
// 将 previous 与 current 的下一项链接起来——跳过 current
previous.next = current.next
current.next.prev = previous // 新增的
}
this.count--
return current.element
}
return undefined
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
# 8. 循环链表
- 循环链表可以像链表一样只有单向引用,也可以像双向链表一样有双向引用。循环链表和链表之间唯一的区别在于,最后一个元素指向下一个元素的指针( tail.next )不是引用 undefined,而是指向第一个元素( head )。
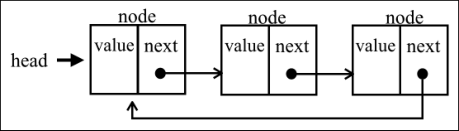
class CircularLinkedList extends LinkedList {
constructor(equalsFn = defaultEquals) {
super(equalsFn)
}
// 在任意位置插入新元素
insert(element, index) {
if (index >= 0 && index <= this.count) {
const node = new Node(element)
let current = this.head
if (index === 0) {
if (this.head == null) {
this.head = node
node.next = this.head // 新增的
} else {
node.next = current
current = this.getElementAt(this.size())
// 更新最后一个元素
this.head = node
current.next = this.head // 新增的
}
} else {
// 这种场景没有变化
const previous = this.getElementAt(index - 1)
node.next = previous.next
previous.next = node
}
this.count++
return true
}
return false
}
// 从任意位置移除元素
removeAt(index) {
if (index >= 0 && index < this.count) {
let current = this.head
if (index === 0) {
if (this.size() === 1) {
this.head = undefined
} else {
const removed = this.head
current = this.getElementAt(this.size()) // 新增的
this.head = this.head.next
current.next = this.head
current = removed
}
} else {
// 不需要修改循环链表最后一个元素
const previous = this.getElementAt(index - 1)
current = previous.next
previous.next = current.next
}
this.count--
return current.element
}
return undefined
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 9. 有序链表
- 有序链表是指保持元素有序的链表结构。除了使用排序算法之外,我们还可以将元素插入到正确的位置来保证链表的有序性。
const Compare = {
LESS_THAN: -1,
BIGGER_THAN: 1,
}
function defaultCompare(a, b) {
if (a === b) {
return 0
}
return a < b ? Compare.LESS_THAN : Compare.BIGGER_THAN
}
class SortedLinkedList extends LinkedList {
constructor(equalsFn = defaultEquals, compareFn = defaultCompare) {
super(equalsFn)
this.compareFn = compareFn
}
// 有序插入元素
insert(element, index = 0) {
if (this.isEmpty()) {
return super.insert(element, 0)
}
return super.insert(element, pos)
}
getIndexNextSortedElement(element) {
let current = this.head
let i = 0
for (; i < this.size() && current; i++) {
const comp = this.compareFn(element, current.element)
if (comp === Compare.LESS_THAN) {
return i
}
current = current.next
}
return i
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 10. 集合
- 集合是由一组无序且唯一(即不能重复)的项组成的。该数据结构使用了与有限集合相同的数学概念,但应用在计算机科学的数据结构中。
class Set {
constructor() {
this.items = {}
}
// 检查是否存在此元素
has(element) {
return Object.prototype.hasOwnProperty.call(this.items, element)
}
// 向集合添加一个新元素
add(element) {
if (!this.has(element)) {
this.items[element] = element
return true
}
return false
}
// 从集合移除一个元素
delete(element) {
if (this.has(element)) {
delete this.items[element]
return true
}
return false
}
// 移除集合中的所有元素
clear() {
this.items = {}
}
// 返回集合所包含元素的数量
size() {
return Object.keys(this.items).length
}
// 返回一个包含集合中所有值(元素)的数组
values() {
return Object.values(this.items)
}
// 并集
union(otherSet) {
const unionSet = new Set()
this.values().forEach(value => unionSet.add(value))
otherSet.values().forEach(value => unionSet.add(value))
return unionSet
}
// 交集
intersection(otherSet) {
const intersectionSet = new Set()
const values = this.values()
const otherValues = otherSet.values()
let biggerSet = values
let smallerSet = otherValues
if (otherValues.length - values.length > 0) {
biggerSet = otherValues
smallerSet = values
}
smallerSet.forEach(value => {
if (biggerSet.includes(value)) {
intersectionSet.add(value)
}
})
return intersectionSet
}
// 差集
difference(otherSet) {
const differenceSet = new Set()
this.values().forEach(value => {
if (!otherSet.has(value)) {
differenceSet.add(value)
}
})
return differenceSet
}
// 子集
isSubsetOf(otherSet) {
if (this.size() > otherSet.size()) {
return false
}
let isSubset = true
this.values().every(value => {
if (!otherSet.has(value)) {
isSubset = false
return false
}
return true
})
return isSubset
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
# 11. 集合运算 - 使用扩展运算符
并集:
new Set([...setA, ...setB]交集:
new Set([...setA].filter(x => setB.has(x)))差集:
new Set([...setA].filter(x => !setB.has(x)))
# 12. 字典
- 在字典中,存储的是[键,值]对,其中键名是用来查询特定元素的。字典和集合很相似,集合以[值,值]的形式存储元素,字典则是以[键,值]的形式来存储元素。字典也称作映射、符号表或关联数组。
function defaultToString(item) {
if (item === null) {
return 'NULL'
} else if (item === undefined) {
return 'UNDEFINED'
} else if (typeof item === 'string' || item instanceof String) {
return `${item}`
}
return item.toString()
}
class ValuePair {
constructor(key, value) {
this.key = key
this.value = value
}
toString() {
return `[#${this.key}: ${this.value}]`
}
}
class Dictionary {
constructor(toStrFn = defaultToString) {
this.toStrFn = toStrFn
this.table = {}
}
// 检测一个键是否存在于字典中
hasKey(key) {
return this.table[this.toStrFn(key)] != null
}
// 在字典和 ValuePair 类中设置键和值
set(key, value) {
if (key != null && value != null) {
const tableKey = this.toStrFn(key)
this.table[tableKey] = new ValuePair(key, value)
return true
}
return false
}
// 从字典中移除一个值
remove(key) {
if (this.hasKey(key)) {
delete this.table[this.toStrFn(key)]
return true
}
return false
}
// 从字典中检索一个值
get(key) {
const valuePair = this.table[this.toStrFn(key)]
return valuePair == null ? undefined : valuePair.value
}
// 获取所有键、值
keyValues() {
return Object.values(this.table)
}
// 获取所有键
keys() {
return this.keyValues().map(valuePair => valuePair.key)
}
// 获取所有值
values() {
return this.keyValues().map(valuePair => valuePair.value)
}
// 用 forEach 迭代字典中的每个键值对
forEach(callbackFn) {
const valuePairs = this.keyValues()
for (let i = 0; i < valuePairs.length; i++) {
const result = callbackFn(valuePairs[i].key, valuePairs[i].value)
if (result === false) {
break
}
}
}
// 获取字典长度
size() {
return Object.keys(this.table).length
}
// 检查字典是否为空
isEmpty() {
return this.size() === 0
}
// 清空字典
clear() {
this.table = {}
}
toString() {
if (this.isEmpty()) {
return ''
}
const valuePairs = this.keyValues()
let objString = `${valuePairs[0].toString()}`
for (let i = 1; i < valuePairs.length; i++) {
objString = `${objString},${valuePairs[i].toString()}`
}
return objString
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
# 13. 散列表
散列算法的作用是尽可能快地在数据结构中找到一个值。在之前的章节中,你已经知道如果要在数据结构中获得一个值(使用 get 方法),需要迭代整个数据结构来找到它。如果使用散列函数,就知道值的具体位置,因此能够快速检索到该值。散列函数的作用是给定一个键值,然后返回值在表中的地址。
散列表有一些在计算机科学中应用的例子。因为它是字典的一种实现,所以可以用作关联数组。它也可以用来对数据库进行索引。当我们在关系型数据库(如 MySQL、Microsoft SQL Server、Oracle,等等)中创建一个新的表时,一个不错的做法是同时创建一个索引来更快地查询到记录的 key 。在这种情况下,散列表可以用来保存键和对表中记录的引用。另一个很常见的应用是使用散列表来表示对象。JavaScript 语言内部就是使用散列表来表示每个对象。此时,对象的每个属性和方法(成员)被存储为 key 对象类型,每个 key 指向对应的对象成员。
class HashTable {
constructor(toStrFn = defaultToString) {
this.toStrFn = toStrFn
this.table = {}
}
// 散列函数
loseloseHashCode(key) {
if (typeof key === 'number') {
return key
}
const tableKey = this.toStrFn(key)
let hash = 0
for (let i = 0; i < tableKey.length; i++) {
hash += tableKey.charCodeAt(i)
}
return hash % 37
}
hashCode(key) {
return this.loseloseHashCode(key)
}
// 将键和值加入散列表
put(key, value) {
if (key != null && value != null) {
const position = this.hashCode(key)
this.table[position] = new ValuePair(key, value)
return true
}
return false
}
// 从散列表中获取一个值
get(key) {
const valuePair = this.table[this.hashCode(key)]
return valuePair == null ? undefined : valuePair.value
}
// 从散列表中移除一个值
remove(key) {
const hash = this.hashCode(key)
const valuePair = this.table[hash]
if (valuePair != null) {
delete this.table[hash]
return true
}
return false
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 14. 处理散列表中的冲突
1.分离链接:分离链接法包括为散列表的每一个位置创建一个链表并将元素存储在里面。它是解决冲突的最简单的方法,但是在 HashTable 实例之外还需要额外的存储空间。
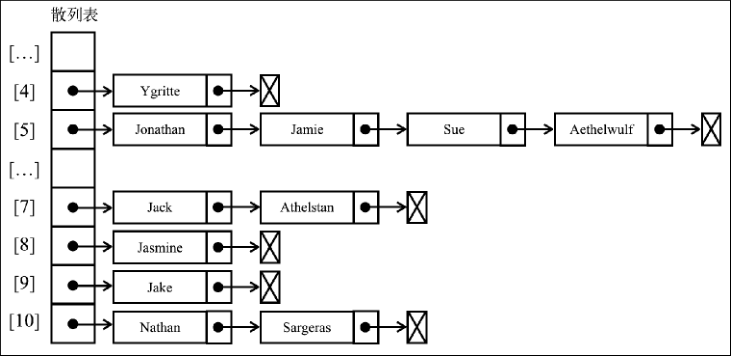
class SeparateHashTable extends HashTable {
put(key, value) {
if (key != null && value != null) {
const position = this.hashCode(key)
if (this.table[position] == null) {
this.table[position] = new LinkedList()
}
this.table[position].push(new ValuePair(key, value))
return true
}
return false
}
get(key) {
const position = this.hashCode(key)
const linkedList = this.table[position]
if (linkedList != null && !linkedList.isEmpty()) {
let current = linkedList.getHead()
while (current != null) {
if (current.element.key === key) {
return current.element.value
}
current = current.next
}
}
return undefined
}
remove(key) {
const position = this.hashCode(key)
const linkedList = this.table[position]
if (linkedList != null && !linkedList.isEmpty()) {
let current = linkedList.getHead()
while (current != null) {
if (current.element.key === key) {
linkedList.remove(current.element)
if (linkedList.isEmpty()) {
delete this.table[position]
}
return true
}
current = current.next
}
}
return false
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
- 线性探查:另一种解决冲突的方法是线性探查。之所以称作线性,是因为它处理冲突的方法是将元素直接存储到表中,而不是在单独的数据结构中。
当想向表中某个位置添加一个新元素的时候,如果索引为 position 的位置已经被占据了,就尝试 position+1 的位置。如果 position+1 的位置也被占据了,就尝试 position+2 的位置,以此类推,直到在散列表中找到一个空闲的位置。想象一下,有一个已经包含一些元素的散列表,我们想要添加一个新的键和值。我们计算这个新键的 hash ,并检查散列表中对应的位置是否被占据。如果没有,我们就将该值添加到正确的位置。如果被占据了,我们就迭代散列表,直到找到一个空闲的位置。
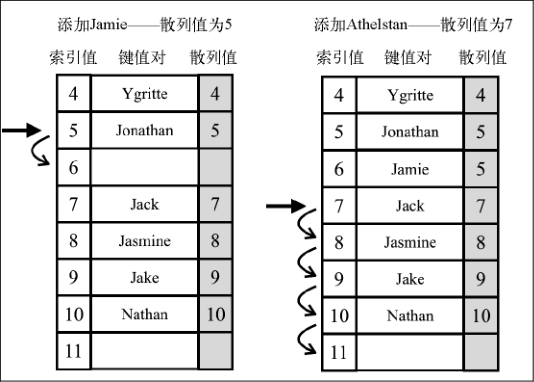
线性探查技术分为两种。第一种是软删除方法。我们使用一个特殊的值(标记)来表示键值对被删除了(惰性删除或软删除),而不是真的删除它。经过一段时间,散列表被操作过后,我们会得到一个标记了若干删除位置的散列表。这会逐渐降低散列表的效率,因为搜索键值会随时间变得更慢。能快速访问并找到一个键是我们使用散列表的一个重要原因。
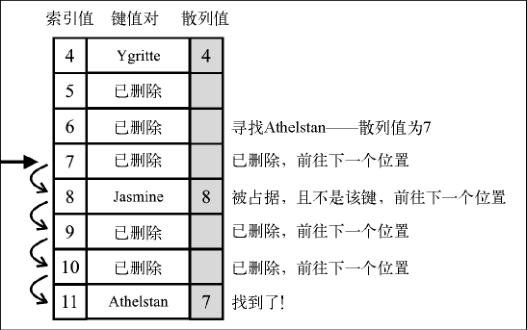
第二种方法需要检验是否有必要将一个或多个元素移动到之前的位置。当搜索一个键的时候,这种方法可以避免找到一个空位置。如果移动元素是必要的,我们就需要在散列表中挪动键值对。
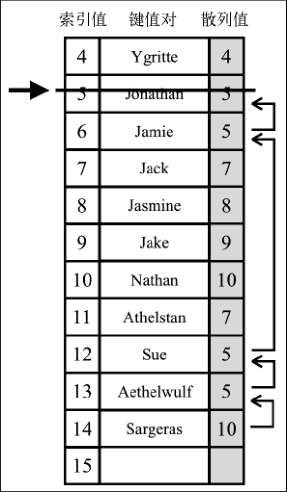
class LinearHashTable extends HashTable {
put(key, value) {
if (key != null && value != null) {
const position = this.hashCode(key)
if (this.table[position] == null) {
} else {
let index = position + 1
while (this.table[index] != null) {
index++
}
this.table[index] = new ValuePair(key, value)
}
return true
}
return false
}
get(key) {
const position = this.hashCode(key)
if (this.table[position] != null) {
if (this.table[position].key === key) {
return this.table[position].value
}
let index = position + 1
while (this.table[index] != null && this.table[index].key !== key) {
index++
}
if (this.table[index] != null && this.table[index].key === key) {
return this.table[position].value
}
}
return undefined
}
remove(key) {
const position = this.hashCode(key)
if (this.table[position] != null) {
if (this.table[position].key === key) {
delete this.table[position]
this.verifyRemoveSideEffect(key, position)
return true
}
let index = position + 1
while (this.table[index] != null && this.table[index].key !== key) {
index++
}
if (this.table[index] != null && this.table[index].key === key) {
delete this.table[index]
this.verifyRemoveSideEffect(key, index)
return true
}
}
return false
}
verifyRemoveSideEffect(key, removedPosition) {
const hash = this.hashCode(key)
let index = removedPosition + 1
while (this.table[index] != null) {
if (posHash <= hash || posHash <= removedPosition) {
this.table[removedPosition] = this.table[index]
delete this.table[index]
removedPosition = index
}
index++
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
# 15. 创建更好的散列函数
djb2HashCode(key) {
const tableKey = this.toStrFn(key)
let hash = 5381
for (let i = 0; i < tableKey.length; i++) {
hash = hash * 33 + tableKey.charCodeAt(i)
}
return hash % 1013
}
2
3
4
5
6
7
8
# 16. 递归
“要理解递归,首先要理解递归。” —— 佚名
阶乘。
function factorial(n) {
if (n === 1 || n === 0) {
return 1
}
return n * factorial(n - 1)
}
2
3
4
5
6
- 斐波那契数。
function fibonacci(n) {
if (n < 1) return 0
if (n <= 2) return 1
return fibonacci(n - 1) + fibonacci(n - 2)
}
// 记忆化斐波那契数
function fibonacciMemoization(n) {
const memo = [0, 1]
const fibonacci = n => {
if (memo[n] != null) return memo[n]
return (memo[n] = fibonacci(n - 1, memo) + fibonacci(n - 2, memo))
}
return fibonacci
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 17. 二叉树和二叉搜索树
二叉树:二叉树中的节点最多只能有两个子节点:一个是左侧子节点,另一个是右侧子节点。这个定义有助于我们写出更高效地在树中插入、查找和删除节点的算法。二叉树在计算机科学中的应用非常广泛。
二叉搜索树:二叉搜索树(BST)是二叉树的一种,但是只允许你在左侧节点存储(比父节点)小的值,在右侧节点存储(比父节点)大的值。
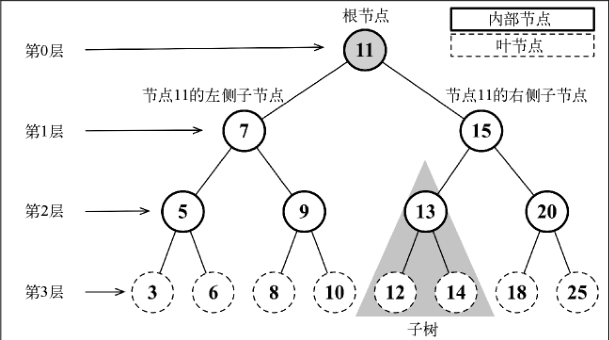
# 18. 创建 BinarySearchTree 类
class Node {
constructor(key) {
this.key = key // 节点值
this.left = null // 左侧子节点引用
this.right = null // 右侧子节点引用
}
}
default class BinarySearchTree {
constructor(compareFn = defaultCompare) {
this.compareFn = compareFn // 用来比较节点值
this.root = null // Node 类型的根节点
}
// 向二叉搜索树中插入一个键
insert(key) {
if (this.root == null) {
this.root = new Node(key)
} else {
this.insertNode(this.root, key)
}
}
insertNode(node, key) {
if (this.compareFn(key, node.key) === Compare.LESS_THAN) {
if (node.left == null) {
node.left = new Node(key)
} else {
this.insertNode(node.left, key)
}
} else {
if (node.right == null) {
node.right = new Node(key)
} else {
this.insertNode(node.right, key)
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 19. 树的遍历
- 中序遍历:中序遍历是一种以上行顺序访问 BST 所有节点的遍历方式,也就是以从最小到最大的顺序访问所有节点。中序遍历的一种应用就是对树进行排序操作。
class InOrderTree extends BinarySearchTree {
inOrderTraverse(callback) {
this.inOrderTraverseNode(this.root, callback)
}
inOrderTraverseNode(node, callback) {
if (node != null) {
this.inOrderTraverseNode(node.left, callback)
callback(node.key)
this.inOrderTraverseNode(node.right, callback)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
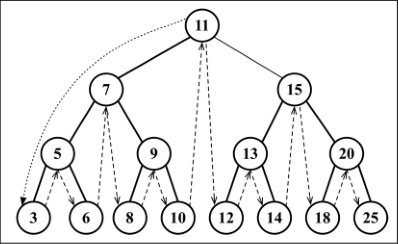
- 先序遍历:先序遍历是以优先于后代节点的顺序访问每个节点的。先序遍历的一种应用是打印一个结构化的文档。
class PreOrderTree extends BinarySearchTree {
preOrderTraverse(callback) {
this.preOrderTraverseNode(this.root, callback)
}
preOrderTraverseNode(node, callback) {
if (node != null) {
callback(node.key)
this.preOrderTraverseNode(node.left, callback)
this.preOrderTraverseNode(node.right, callback)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
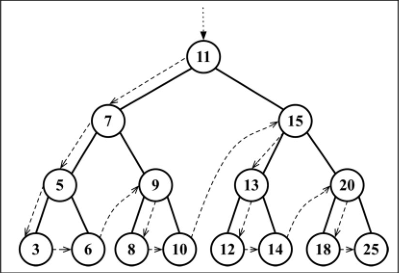
- 后序遍历:后序遍历则是先访问节点的后代节点,再访问节点本身。后序遍历的一种应用是计算一个目录及其子目录中所有文件所占空间的大小。
class PostOrderTree extends BinarySearchTree {
postOrderTraverse(callback) {
this.postOrderTraverseNode(this.root, callback)
}
postOrderTraverseNode(node, callback) {
if (node != null) {
this.postOrderTraverseNode(node.left, callback)
this.postOrderTraverseNode(node.right, callback)
callback(node.key)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
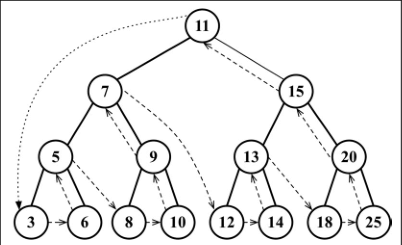
# 20. 搜索树中的值
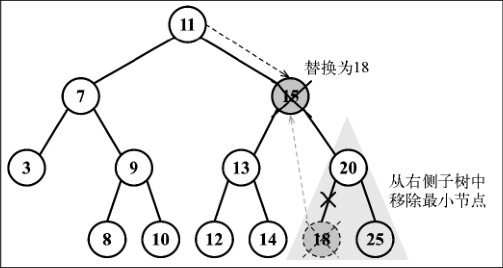
要移除有两个子节点的节点,需要执行四个步骤。
- 当找到了要移除的节点后,需要找到它右边子树中最小的节点。
- 然后,用它右侧子树中最小节点的键去更新这个节点的值。通过这一步,我们改变了这个节点的键,也就是说它被移除了。
- 但是,这样在树中就有两个拥有相同键的节点了,这是不行的。要继续把右侧子树中的最小节点移除,毕竟它已经被移至要移除的节点的位置了。
- 最后,向它的父节点返回更新后节点的引用。
class Tree extends BinarySearchTree {
// 搜索最小值
min() {
return this.minNode(this.root)
}
minNode(node) {
let current = node
while (current != null && current.left != null) {
current = current.left
}
return current
}
// 搜索最大值
max() {
return this.maxNode(this.root)
}
maxNode(node) {
let current = node
while (current != null && current.right != null) {
current = current.right
}
return current
}
// 搜索一个特定的值
search(key) {
return this.searchNode(this.root, key)
}
searchNode(node, key) {
if (node == null) {
return false
}
if (this.compareFn(key, node.key) === Compare.LESS_THAN) {
return this.searchNode(node.left, key)
} else if (this.compareFn(key, node.key) === Compare.BIGGER_THAN) {
return this.searchNode(node.right, key)
} else {
return true
}
}
// 移除一个节点
removeNode(node, key) {
if (node == null) {
return null
}
if (this.compareFn(key, node.key) === Compare.LESS_THAN) {
node.left = this.removeNode(node.left, key)
return node
} else if (this.compareFn(key, node.key) === Compare.BIGGER_THAN) {
node.right = this.removeNode(node.right, key)
return node
} else {
// 键等于 node.key
// 第一种情况
if (node.left == null && node.right == null) {
node = null
return node
}
// 第二种情况
if (node.left == null) {
node = node.right
return node
} else if (node.right == null) {
node = node.left
return node
}
// 第三种情况
const aux = this.minNode(node.right)
node.key = aux.key
node.right = this.removeNode(node.right, aux.key)
return node
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
# 21. 自平衡树
- BST 存在一个问题:取决于你添加的节点数,树的一条边可能会非常深。也就是说,树的一条分支会有很多层,而其他的分支却只有几层。这会在需要在某条边上添加、移除和搜索某个节点时引起一些性能问题。为了解决这个问题,有一种树叫作 Adelson-Velskii-Landi 树(AVL 树)。AVL 树是一种自平衡二叉搜索树,意思是任何一个节点左右两侧子树的高度之差最多为 1。
# 22. Adelson-Velskii-Landi 树(AVL 树)
节点的高度和平衡因子
- 节点的高度是从节点到其任意子节点的边的最大值。
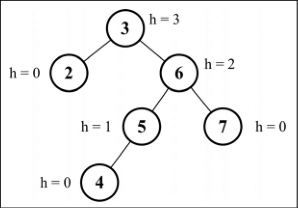
- 在 AVL 树中,需要对每个节点计算右子树高度( hr )和左子树高度( hl )之间的差值,该值( hr-hl )应为 0、1 或 -1。如果结果不是这三个值之一,则需要平衡该 AVL 树。这就是平衡因子的概念。
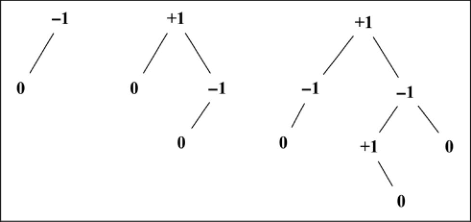
平衡操作——AVL 旋转
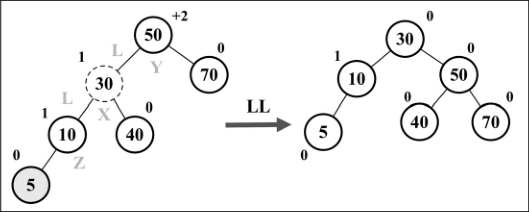
- 左 - 左(LL):向右的单旋转。
- 与平衡操作相关的节点有三个(X、Y、Z),将节点 X 置于节点 Y(平衡因子为+2)所在的位置。
- 节点 X 的左子树保持不变。
- 将节点 Y 的左子节点置为节点 X 的右子节点 Z。
- 将节点 X 的右子节点置为节点 Y。
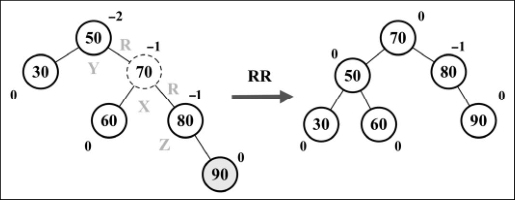
- 右 - 右(RR):向左的单旋转。
- 与平衡操作相关的节点有三个(X、Y、Z),将节点 X 置于节点 Y(平衡因子为-2)所在的位置。
- 节点 X 的右子树保持不变。
- 将节点 Y 的右子节点置为节点 X 的左子节点 Z。
- 将节点 X 的左子节点置为节点 Y。
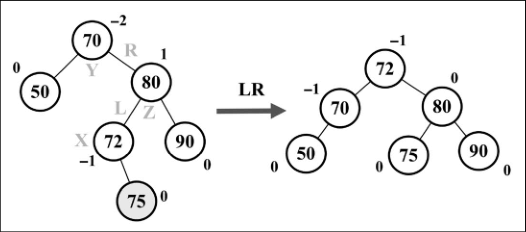
- 左 - 右(LR):向右的双旋转。
- 将节点 X 置于节点 Y(平衡因子为 -2)所在的位置。
- 将节点 Z 的左子节点置为节点 X 的右子节点。
- 将节点 Y 的右子节点置为节点 X 的左子节点。
- 将节点 X 的右子节点置为节点 Y。
- 将节点 X 的左子节点置为节点 Z。
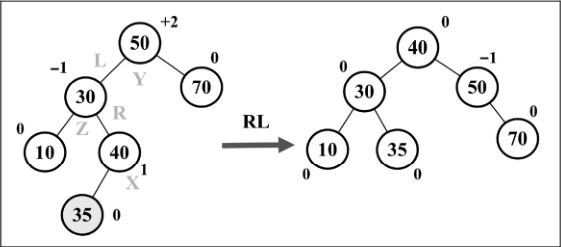
- 右 - 左(RL):向左的双旋转。
- 将节点 X 置于节点 Y(平衡因子为+2)所在的位置。
- 将节点 Y 的左子节点置为节点 X 的右子节点。
- 将节点 Z 的右子节点置为节点 X 的左子节点。
- 将节点 X 的左子节点置为节点 Y。
- 将节点 X 的右子节点置为节点 Z。
const BalanceFactor = {
UNBALANCED_RIGHT: 1,
SLIGHTLY_UNBALANCED_RIGHT: 2,
BALANCED: 3,
SLIGHTLY_UNBALANCED_LEFT: 4,
UNBALANCED_LEFT: 5,
}
class AVLTree extends BinarySearchTree {
constructor(compareFn = defaultCompare) {
super(compareFn)
this.compareFn = compareFn
this.root = null
}
// 节点高度
getNodeHeight(node) {
if (node == null) {
return -1
}
return (
Math.max(this.getNodeHeight(node.left), this.getNodeHeight(node.right)) +
1
)
}
// 平衡因子
getBalanceFactor(node) {
const heightDifference =
this.getNodeHeight(node.left) - this.getNodeHeight(node.right)
switch (heightDifference) {
case -2:
return BalanceFactor.UNBALANCED_RIGHT
case -1:
return BalanceFactor.SLIGHTLY_UNBALANCED_RIGHT
case 1:
return BalanceFactor.SLIGHTLY_UNBALANCED_LEFT
case 2:
return BalanceFactor.UNBALANCED_LEFT
default:
return BalanceFactor.BALANCED
}
}
// 向右的单旋转
rotationLL(node) {
const tmp = node.left
node.left = tmp.right
tmp.right = node
return tmp
}
// 向左的单旋转
rotationRR(node) {
const tmp = node.right
node.right = tmp.left
tmp.left = node
return tmp
}
// 向右的双旋转
rotationLR(node) {
node.left = this.rotationRR(node.left)
return this.rotationLL(node)
}
// 向左的双旋转
rotationRL(node) {
node.right = this.rotationLL(node.right)
return this.rotationRR(node)
}
// 向 AVL 树插入节点
insert(key) {
this.root = this.insertNode(this.root, key)
}
insertNode(node, key) {
// 像在 BST 树中一样插入节点
if (node == null) {
return new Node(key)
} else if (this.compareFn(key, node.key) === Compare.LESS_THAN) {
node.left = this.insertNode(node.left, key)
} else if (this.compareFn(key, node.key) === Compare.BIGGER_THAN) {
node.right = this.insertNode(node.right, key)
} else {
return node // 重复的键
}
// 如果需要,将树进行平衡操作
const balanceFactor = this.getBalanceFactor(node)
if (balanceFactor === BalanceFactor.UNBALANCED_LEFT) {
if (this.compareFn(key, node.left.key) === Compare.LESS_THAN) {
node = this.rotationLL(node)
} else {
return this.rotationLR(node)
}
}
if (balanceFactor === BalanceFactor.UNBALANCED_RIGHT) {
if (this.compareFn(key, node.right.key) === Compare.BIGGER_THAN) {
node = this.rotationRR(node)
} else {
return this.rotationRL(node)
}
}
return node
}
// 从 AVL 树中移除节点
removeNode(node, key) {
node = super.removeNode(node, key)
if (node == null) {
return node // null,不需要进行平衡
}
// 检测树是否平衡
const balanceFactor = this.getBalanceFactor(node)
if (balanceFactor === BalanceFactor.UNBALANCED_LEFT) {
const balanceFactorLeft = this.getBalanceFactor(node.left)
if (
balanceFactorLeft === BalanceFactor.BALANCED ||
balanceFactorLeft === BalanceFactor.SLIGHTLY_UNBALANCED_LEFT
) {
return this.rotationLL(node)
}
if (balanceFactorLeft === BalanceFactor.SLIGHTLY_UNBALANCED_RIGHT) {
return this.rotationLR(node.left)
}
}
if (balanceFactor === BalanceFactor.UNBALANCED_RIGHT) {
const balanceFactorRight = this.getBalanceFactor(node.right)
if (
balanceFactorRight === BalanceFactor.BALANCED ||
balanceFactorRight === BalanceFactor.SLIGHTLY_UNBALANCED_RIGHT
) {
return this.rotationRR(node)
}
if (balanceFactorRight === BalanceFactor.SLIGHTLY_UNBALANCED_LEFT) {
return this.rotationRL(node.right)
}
}
return node
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
# 23. 红黑树
和 AVL 树一样,红黑树也是一个自平衡二叉搜索树。我们学习了对 AVL 书插入和移除节点可能会造成旋转,所以我们需要一个包含多次插入和删除的自平衡树,红黑树是比较好的。如果插入和删除频率较低(我们更需要多次进行搜索操作),那么 AVL 树比红黑树更好。
在红黑树中,每个节点都遵循以下规则。
- 顾名思义,每个节点不是红的就是黑的。
- 树的根节点是黑的。
- 所有叶节点都是黑的(用 NULL 引用表示的节点)。
- 如果一个节点是红的,那么它的两个子节点都是黑的。
- 不能有两个相邻的红节点,一个红节点不能有红的父节点或子节点。
- 从给定的节点到它的后代节点( NULL 叶节点)的所有路径包含相同数量的黑色节点。
class RedBlackNode extends Node {
constructor(key) {
super(key)
this.key = key
this.color = Colors.RED
this.parent = null
}
isRed() {
return this.color === Colors.RED
}
}
class RedBlackTree extends BinarySearchTree {
constructor(compareFn = defaultCompare) {
super(compareFn)
this.compareFn = compareFn
this.root = null
}
// 向红黑树插入节点
insert(key) {
if (this.root == null) {
this.root = new RedBlackNode(key)
this.root.color = Colors.BLACK
} else {
const newNode = this.insertNode(this.root, key)
this.fixTreeProperties(newNode)
}
}
insertNode(node, key) {
if (this.compareFn(key, node.key) === Compare.LESS_THAN) {
if (node.left == null) {
node.left = new RedBlackNode(key)
node.left.parent = node
return node.left
} else {
return this.insertNode(node.left, key)
}
} else if (node.right == null) {
node.right = new RedBlackNode(key)
node.right.parent = node
return node.right
} else {
return this.insertNode(node.right, key)
}
}
fixTreeProperties(node) {
while (
node &&
node.parent &&
node.parent.color.isRed() &&
node.color !== Colors.BLACK
) {
let parent = node.parent
const grandParent = parent.parent
// 情形 A:父节点是左侧子节点
if (grandParent && grandParent.left === parent) {
const uncle = grandParent.right
// 情形 1A:叔节点也是红色——只需要重新填色
if (uncle && uncle.color === Colors.RED) {
grandParent.color = Colors.RED
parent.color = Colors.BLACK
uncle.color = Colors.BLACK
node = grandParent
} else {
// 情形 2A:节点是右侧子节点——左旋转
if (node === parent.right) {
this.rotationRR(parent)
node = parent
parent = node.parent
}
// 情形 3A:节点是左侧子节点——右旋转
this.rotationLL(grandParent)
parent.color = Colors.BLACK
grandParent.color = Colors.RED
node = parent
}
} else {
// 情形 B:父节点是右侧子节点
const uncle = grandParent.left
// 情形 1B:叔节点是红色——只需要重新填色
if (uncle && uncle.color === Colors.RED) {
grandParent.color = Colors.RED
parent.color = Colors.BLACK
uncle.color = Colors.BLACK
node = grandParent
} else {
// 情形 2B:节点是左侧子节点——右旋转
if (node === parent.left) {
this.rotationLL(parent)
node = parent
parent = node.parent
}
// 情形 3B:节点是右侧子节点——左旋转
this.rotationRR(grandParent)
parent.color = Colors.BLACK
grandParent.color = Colors.RED
node = parent
}
}
}
this.root.color = Colors.BLACK
}
rotationLL(node) {
const tmp = node.left
node.left = tmp.right
if (tmp.right && tmp.right.key) {
tmp.right.parent = node
}
tmp.parent = node.parent
if (!node.parent) {
this.root = tmp
} else {
if (node === node.parent.left) {
node.parent.left = tmp
} else {
node.parent.right = tmp
}
}
tmp.right = node
node.parent = tmp
}
rotationRR(node) {
const tmp = node.right
node.right = tmp.left
if (tmp.left && tmp.left.key) {
tmp.left.parent = node
}
tmp.parent = node.parent
if (!node.parent) {
this.root = tmp
} else {
if (node === node.parent.left) {
node.parent.left = tmp
} else {
node.parent.right = tmp
}
}
tmp.left = node
node.parent = tmp
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
# 24. 二叉堆数据结构
二叉堆是计算机科学中一种非常著名的数据结构,由于它能高效、快速地找出最大值和最小值,常被应用于优先队列。它也被用于著名的堆排序算法中。
二叉堆是一种特殊的二叉树,有以下两个特性。
- 它是一棵完全二叉树,表示树的每一层都有左侧和右侧子节点(除了最后一层的叶节点),并且最后一层的叶节点尽可能都是左侧子节点,这叫作结构特性。
- 二叉堆不是最小堆就是最大堆。最小堆允许你快速导出树的最小值,最大堆允许你快速导出树的最大值。所有的节点都大于等于(最大堆)或小于等于(最小堆)每个它的子节点。这叫作堆特性。
尽管二叉堆是二叉树,但并不一定是二叉搜索树(BST)。在二叉堆中,每个子节点都要大于等于父节点(最小堆)或小于等于父节点(最大堆)。然而在二叉搜索树中,左侧子节点总是比父节点小,右侧子节点也总是更大。
创建最小堆类
function swap(array, a, b) {
const temp = array[a]
array[a] = array[b]
array[b] = temp
}
class MinHeap {
constructor(compareFn = defaultCompare) {
this.compareFn = compareFn
this.heap = []
}
getLeftIndex(index) {
return 2 * index + 1
}
getRightIndex(index) {
return 2 * index + 2
}
getParentIndex(index) {
if (index === 0) {
return undefined
}
return Math.floor((index - 1) / 2)
}
// 向堆中插入值
insert(value) {
if (value != null) {
this.heap.push(value)
this.siftUp(this.heap.length - 1)
return true
}
return false
}
// 上移操作
siftUp(index) {
let parent = this.getParentIndex(index)
while (
index > 0 &&
this.compareFn(this.heap[parent], this.heap[index]) > Compare.BIGGER_THAN
) {
swap(this.heap, parent, index)
index = parent
parent = this.getParentIndex(index)
}
}
size() {
return this.heap.length
}
isEmpty() {
return this.size() === 0
}
// 寻找最小值
findMinimum() {
return this.isEmpty() ? undefined : this.heap[0]
}
// 导出堆中的最小值或最大值
extract() {
if (this.isEmpty()) {
return undefined
}
if (this.size() === 1) {
return this.heap.shift()
}
const removedValue = this.heap.shift()
this.siftDown(0)
return removedValue
}
// 下移操作(堆化)
siftDown(index) {
let element = index
const left = this.getLeftIndex(index)
const right = this.getRightIndex(index)
const size = this.size()
if (
left < size &&
this.compareFn(this.heap[element], this.heap[left]) > Compare.BIGGER_THAN
) {
element = left
}
if (
right < size &&
this.compareFn(this.heap[element], this.heap[right]) > Compare.BIGGER_THAN
) {
element = right
}
if (index !== element) {
swap(this.heap, index, element)
this.siftDown(element)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
创建最大堆类
MaxHeap 类的算法和 MinHeap 类的算法一模一样。不同之处在于我们要把所有 > (大于)的比较换成 < (小于)的比较。
function reverseCompare(compareFn) {
return (a, b) => compareFn(b, a)
}
class MaxHeap extends MinHeap {
constructor(compareFn = defaultCompare) {
super(compareFn)
this.compareFn = reverseCompare(compareFn)
}
}
2
3
4
5
6
7
8
9
10
# 25. 堆排序算法
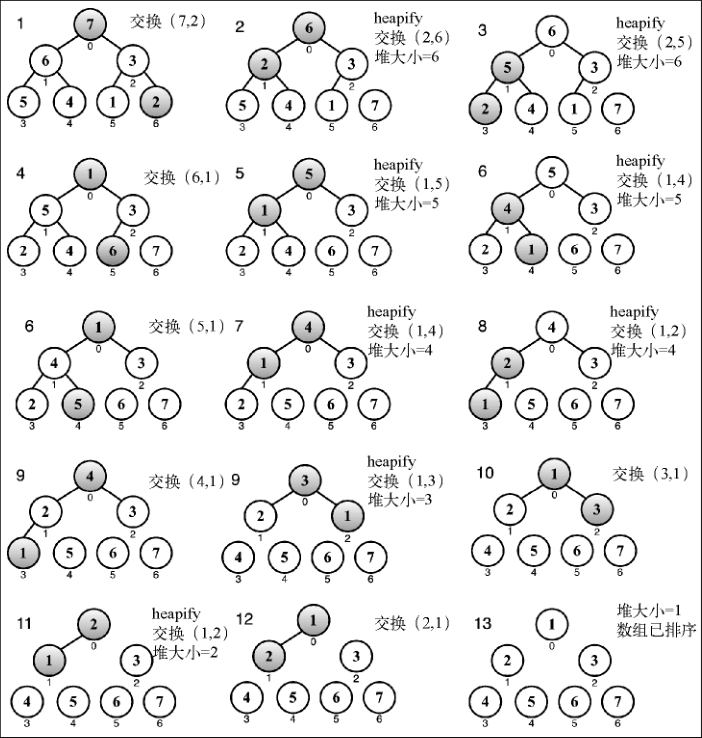
我们可以使用二叉堆数据结构来帮助我们创建一个非常著名的排序算法:堆排序算法。它包含下面三个步骤。
- 用数组创建一个最大堆用作源数据。
- 在创建最大堆后,最大的值会被存储在堆的第一个位置。我们要将它替换为堆的最后一个值,将堆的大小减 1。
- 最后,我们将堆的根节点下移并重复步骤 2 直到堆的大小为 1。
heapify 函数和我们创建的 siftDown 方法有相同的代码。不同之处是我们会将堆本身、堆的大小和要使用的比较函数传入作为参数。这是因为我们不会直接使用堆数据结构,而是使用它的逻辑来开发 heapSort 算法。
function heapSort(array, compareFn = defaultCompare) {
let heapSize = array.length
buildMaxHeap(array, compareFn)
while (heapSize > 1) {
swap(array, 0, --heapSize)
heapify(array, 0, heapSize, compareFn)
}
return array
}
function buildMaxHeap(array, compareFn) {
for (let i = Math.floor(array.length / 2); i >= 0; i -= 1) {
heapify(array, i, array.length, compareFn)
}
return array
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 26. 图的相关术语
图是网络结构的抽象模型。图是一组由边连接的节点(或顶点)。学习图是重要的,因为任何二元关系都可以用图来表示。
有向图和无向图:图可以是无向的(边没有方向)或是有向的(有向图)。
# 27. 图的表示
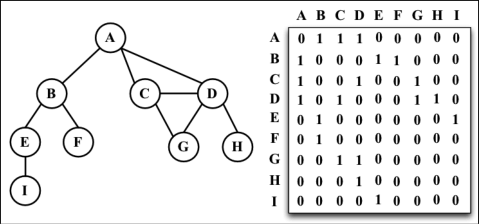
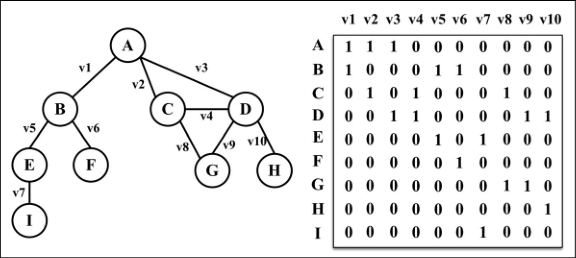
- 邻接矩阵:图最常见的实现是邻接矩阵。每个节点都和一个整数相关联,该整数将作为数组的索引。我们用一个二维数组来表示顶点之间的连接。
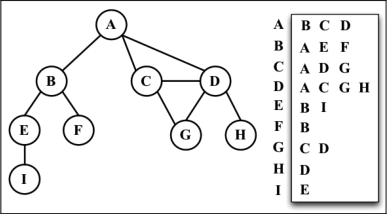
- 邻接表:邻接表由图中每个顶点的相邻顶点列表所组成。存在好几种方式来表示这种数据结构。我们可以用列表(数组)、链表,甚至是散列表或是字典来表示相邻顶点列表。
- 关联矩阵:还可以用关联矩阵来表示图。在关联矩阵中,矩阵的行表示顶点,列表示边。
# 28. 创建 Graph 类
class Graph {
constructor(isDirected = false) {
this.isDirected = isDirected
this.vertices = []
this.adjList = new Dictionary()
}
// 这个方法接收顶点 v 作为参数。只有在这个顶点不存在于图中时我们将该顶点添加到顶点列表中,并且在邻接表中,设置顶点 v 作为键对应的字典值为一个空数组。
addVertex(v) {
if (!this.vertices.includes(v)) {
this.vertices.push(v)
this.adjList.set(v, [])
}
}
// 这个方法接收两个顶点作为参数,也就是我们要建立连接的两个顶点。在连接顶点之前,需要验证顶点是否存在于图中。如果顶点 v 或 w 不存在于图中,要将它们加入顶点列表。
addEdge(v, w) {
if (!this.adjList.get(v)) {
this.addVertex(v)
}
if (!this.adjList.get(w)) {
this.addVertex(w)
}
this.adjList.get(v).push(w)
if (!this.isDirected) {
this.adjList.get(w).push(v)
}
}
// 返回顶点列表
getVertices() {
return this.vertices
}
// 返回邻接表
getAdjList() {
return this.adjList
}
toString() {
let s = ''
for (let i = 0; i < this.vertices.length; i++) {
s += `${this.vertices[i]} -> `
const neighbors = this.adjList.get(this.vertices[i])
for (let j = 0; j < neighbors.length; j++) {
s += `${neighbors[j]} `
}
s += '\n'
}
return s
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 29. 图的遍历
和树数据结构类似,我们可以访问图的所有节点。有两种算法可以对图进行遍历:广度优先搜索(breadth-first search,BFS)和深度优先搜索(depth-first search,DFS)。图遍历可以用来寻找特定的顶点或寻找两个顶点之间的路径,检查图是否连通,检查图是否含有环,等等。
当要标注已经访问过的顶点时,我们用三种颜色来反映它们的状态。
- 白色:表示该顶点还没有被访问。
- 灰色:表示该顶点被访问过,但并未被探索过。
- 黑色:表示该顶点被访问过且被完全探索过。
const Colors = {
WHITE: 0,
GREY: 1,
BLACK: 2,
}
// 初始化每个顶点的颜色
const initializeColor = vertices => {
const color = {}
for (let i = 0; i < vertices.length; i++) {
color[vertices[i]] = Colors.WHITE
}
return color
}
2
3
4
5
6
7
8
9
10
11
12
13
14
深度优先搜索
- 数据结构:栈
- 描述:将顶点存入栈,顶点是沿着路径被探索的,存在新的相邻顶点就去访问
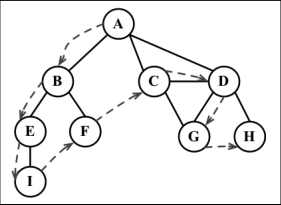
const depthFirstSearch = (graph, callback) => {
const vertices = graph.getVertices()
const adjList = graph.getAdjList()
const color = initializeColor(vertices)
for (let i = 0; i < vertices.length; i++) {
if (color[vertices[i]] === Colors.WHITE) {
depthFirstSearchVisit(vertices[i], color, adjList, callback)
}
}
}
const depthFirstSearchVisit = (u, color, adjList, callback) => {
color[u] = Colors.GREY
if (callback) {
callback(u)
}
// 邻接表
const neighbors = adjList.get(u)
for (let i = 0; i < neighbors.length; i++) {
const w = neighbors[i]
if (color[w] === Colors.WHITE) {
depthFirstSearchVisit(w, color, adjList, callback)
}
}
color[u] = Colors.BLACK
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
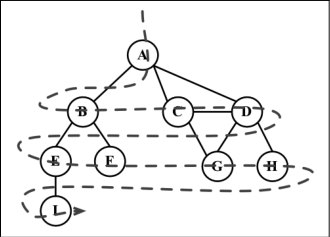
广度优先搜索
- 数据结构:队列
- 描述:将顶点存入队列,最先入队列的顶点先被探索
const breadthFirstSearch = (graph, startVertex, callback) => {
const vertices = graph.getVertices()
const adjList = graph.getAdjList()
const color = initializeColor(vertices)
const queue = new Queue()
queue.enqueue(startVertex)
while (!queue.isEmpty()) {
const u = queue.dequeue()
// 邻接表
const neighbors = adjList.get(u)
color[u] = Colors.GREY
for (let i = 0; i < neighbors.length; i++) {
const w = neighbors[i]
if (color[w] === Colors.WHITE) {
color[w] = Colors.GREY
queue.enqueue(w)
}
}
color[u] = Colors.BLACK
if (callback) {
callback(u)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 30. 分而治之
分而治之是算法设计中的一种方法。它将一个问题分成多个和原问题相似的小问题,递归解决小问题,再将解决方式合并以解决原来的问题。
分而治之算法可以分成三个部分。
- 分解原问题为多个子问题(原问题的多个小实例)。
- 解决子问题,用返回解决子问题的方式的递归算法。递归算法的基本情形可以用来解决子问题。
- 组合这些子问题的解决方式,得到原问题的解。
# 31. 动态规划
动态规划(dynamic programming,DP)是一种将复杂问题分解成更小的子问题来解决的优化技术。
注意,动态规划和分而治之是不同的方法。分而治之方法是把问题分解成相互独立的子问题,然后组合它们的答案,而动态规划则是将问题分解成相互依赖的子问题。
最少硬币找零问题。
最少硬币找零问题是硬币找零问题的一个变种。硬币找零问题是给出要找零的钱数,以及可用的硬币面额 d 1 , …, d n 及其数量,找出有多少种找零方法。最少硬币找零问题是给出要找零的钱数,以及可用的硬币面额 d 1 , …, d n 及其数量,找到所需的最少的硬币个数。
function minCoinChange(coins, amount) {
const cache = []
const makeChange = value => {
if (!value) {
return []
}
if (cache[value]) {
return cache[value]
}
let min = []
let newMin
let newAmount
for (let i = 0; i < coins.length; i++) {
const coin = coins[i]
newAmount = value - coin
if (newAmount >= 0) {
newMin = makeChange(newAmount)
}
if (
newAmount >= 0 &&
(newMin.length < min.length - 1 || !min.length) &&
(newMin.length || !newAmount)
) {
min = [coin].concat(newMin)
console.log('new Min ' + min + ' for ' + amount)
}
}
return (cache[value] = min)
}
return makeChange(amount)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
背包问题。
背包问题是一个组合优化问题。它可以描述如下:给定一个固定大小、能够携重量 W 的背包,以及一组有价值和重量的物品,找出一个最佳解决方案,使得装入背包的物品总重量不超过 W,且总价值最大。
function knapSack(capacity, weights, values, n) {
const kS = []
for (let i = 0; i <= n; i++) {
kS[i] = []
}
for (let i = 0; i <= n; i++) {
for (let w = 0; w <= capacity; w++) {
if (i === 0 || w === 0) {
kS[i][w] = 0
} else if (weights[i - 1] <= w) {
const a = values[i - 1] + kS[i - 1][w - weights[i - 1]]
const b = kS[i - 1][w]
kS[i][w] = a > b ? a : b // max(a,b)
} else {
kS[i][w] = kS[i - 1][w]
}
}
}
// 请注意,这个算法只输出背包携带物品价值的最大值,而不列出实际的物品。我们可以增加下面的附加函数来找出构成解决方案的物品。
findValues(n, capacity, kS, weights, values) // 增加的代码
return kS[n][capacity]
}
function findValues(n, capacity, kS, weights, values) {
let i = n
let k = capacity
console.log('构成解的物品:')
while (i > 0 && k > 0) {
if (kS[i][k] !== kS[i - 1][k]) {
console.log(
`物品 ${i} 可以是解的一部分 w,v: ${weights[i - 1]}, ${values[i - 1]}`
)
i--
k -= kS[i][k]
} else {
i--
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
最长公共子序列。
另一个经常被当作编程挑战问题的动态规划问题是最长公共子序列(LCS):找出两个字符串序列的最长子序列的长度。最长子序列是指,在两个字符串序列中以相同顺序出现,但不要求连续(非字符串子串)的字符串序列。
function lcs(wordX, wordY) {
const m = wordX.length
const n = wordY.length
const l = []
for (let i = 0; i <= m; i++) {
l[i] = []
for (let j = 0; j <= n; j++) {
l[i][j] = 0
}
}
for (let i = 0; i <= m; i++) {
for (let j = 0; j <= n; j++) {
if (i === 0 || j === 0) {
l[i][j] = 0
} else if (wordX[i - 1] === wordY[j - 1]) {
l[i][j] = l[i - 1][j - 1] + 1
} else {
const a = l[i - 1][j]
const b = l[i][j - 1]
l[i][j] = a > b ? a : b // max(a,b)
}
}
}
return l[m][n]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
矩阵链相乘。
- 矩阵链相乘是另一个可以用动态规划解决的著名问题。这个问题是要找出一组矩阵相乘的最佳方式(顺序)。
- 让我们试着更好地理解这个问题。n 行 m 列的矩阵 A 和 m 行 p 列的矩阵 B 相乘,结果是 n 行 p 列的矩阵 C。
- 考虑我们想做 A*B*C*D 的乘法。因为乘法满足结合律,所以我们可以让这些矩阵以任意顺序相乘。因此,考虑如下情况:
- A 是一个 10 行 100 列的矩阵。
- B 是一个 100 行 5 列的矩阵。
- C 是一个 5 行 50 列的矩阵。
- D 是一个 50 行 1 列的矩阵。
- A*B*C*D 的结果是一个 10 行 1 列的矩阵。
- 在这个例子里,相乘的方式有五种。
- (A(B(CD))):乘法运算的次数是 1750 次。
- ((AB)(CD)):乘法运算的次数是 5300 次。
- (((AB)C)D):乘法运算的次数是 8000 次。
- ((A(BC))D):乘法运算的次数是 75 500 次。
- (A((BC)D)):乘法运算的次数是 31 000 次。
function matrixChainOrder(p) {
const n = p.length
const m = []
const s = []
for (let i = 1; i <= n; i++) {
m[i] = []
m[i][i] = 0
}
for (let l = 2; l < n; l++) {
for (let i = 1; i <= n - l + 1; i++) {
const j = i + l - 1
m[i][j] = Number.MAX_SAFE_INTEGER
for (let k = i; k <= j - 1; k++) {
const q = m[i][k] + m[k + 1][j] + p[i - 1] * p[k] * p[j]
if (q < m[i][j]) {
m[i][j] = q
}
}
}
}
return m[1][n - 1]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 32. 贪心算法
贪心算法遵循一种近似解决问题的技术,期盼通过每个阶段的局部最优选择(当前最好的解),从而达到全局的最优(全局最优解)。它不像动态规划算法那样计算更大的格局。
最少硬币找零问题。
最少硬币找零问题也能用贪心算法解决。大部分情况下的结果是最优的,不过对有些面额而言,结果不会是最优的。
function minCoinChange(coins, amount) {
const change = []
let total = 0
for (let i = coins.length; i >= 0; i--) {
const coin = coins[i]
while (total + coin <= amount) {
change.push(coin)
total += coin
}
}
return change
}
2
3
4
5
6
7
8
9
10
11
12
分数背包问题。
求解分数背包问题的算法与动态规划版本稍有不同。在 0-1 背包问题中,只能向背包里装入完整的物品,而在分数背包问题中,可以装入分数(%)的物品。
function knapSack(capacity, weights, values) {
const n = values.length
let load = 0
let val = 0
for (let i = 0; i < n && load < capacity; i++) {
if (weights[i] <= capacity - load) {
val += values[i]
load += weights[i]
} else {
const r = (capacity - load) / weights[i]
val += r * values[i]
load += weights[i]
}
}
return val
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 33. 回溯算法
回溯是一种渐进式寻找并构建问题解决方式的策略。我们从一个可能的动作开始并试着用这个动作解决问题。如果不能解决,就回溯并选择另一个动作直到将问题解决。根据这种行为,回溯算法会尝试所有可能的动作(如果更快找到了解决办法就尝试较少的次数)来解决问题。
迷宫老鼠问题。
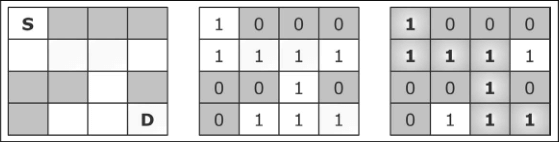
- 假设我们有一个大小为 N × N 的矩阵,矩阵的每个位置是一个方块。每个位置(或块)可以是空闲的(值为 1)或是被阻挡的(值为 0),如下图所示,其中 S 是起点,D 是终点。
- 矩阵就是迷宫,“老鼠”的目标是从位置 [0][0] 开始并移动到 [n-1][n-1] (终点)。老鼠可以在垂直或水平方向上任何未被阻挡的位置间移动。
function ratInAMaze(maze) {
const solution = []
for (let i = 0; i < maze.length; i++) {
solution[i] = []
for (let j = 0; j < maze[i].length; j++) {
solution[i][j] = 0
}
}
if (findPath(maze, 0, 0, solution) === true) {
return solution
}
return 'NO PATH FOUND'
}
function findPath(maze, x, y, solution) {
const n = maze.length
if (x === n - 1 && y === n - 1) {
solution[x][y] = 1
return true
}
if (isSafe(maze, x, y) === true) {
solution[x][y] = 1
if (findPath(maze, x + 1, y, solution)) {
return true
}
if (findPath(maze, x, y + 1, solution)) {
return true
}
solution[x][y] = 0
return false
}
return false
}
function isSafe(maze, x, y) {
const n = maze.length
if (x >= 0 && y >= 0 && x < n && y < n && maze[x][y] !== 0) {
return true
}
return false
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 34. 数独解题器
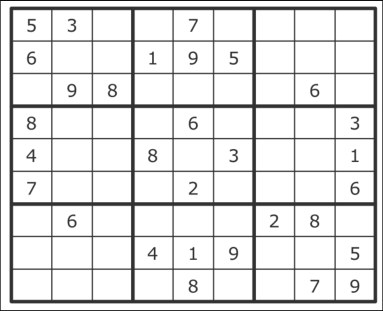
- 数独是一个非常有趣的解谜游戏,也是史上最流行的游戏之一。目标是用数字 1 ~ 9 填满一个 9 × 9 的矩阵,要求每行和每列都由这九个数字构成。矩阵还包含了小方块(3 × 3 矩阵),它们同样需要分别用这九个数字填满。谜题在开始给出一个已填了部分数字的矩阵,如下图所示。
function sudokuSolver(matrix) {
if (solveSudoku(matrix) === true) {
return matrix
}
return '问题无解!'
}
const UNASSIGNED = 0
function solveSudoku(matrix) {
let row = 0
let col = 0
let checkBlankSpaces = false
for (row = 0; row < matrix.length; row++) {
for (col = 0; col < matrix[row].length; col++) {
if (matrix[row][col] === UNASSIGNED) {
checkBlankSpaces = true
break
}
}
if (checkBlankSpaces === true) {
break
}
}
if (checkBlankSpaces === false) {
return true
}
for (let num = 1; num <= 9; num++) {
if (isSafe(matrix, row, col, num)) {
matrix[row][col] = num
if (solveSudoku(matrix)) {
return true
}
matrix[row][col] = UNASSIGNED
}
}
return false
}
function isSafe(matrix, row, col, num) {
return (
!usedInRow(matrix, row, num) &&
!usedInCol(matrix, col, num) &&
!usedInBox(matrix, row - (row % 3), col - (col % 3), num)
)
}
function usedInRow(matrix, row, num) {
for (let col = 0; col < matrix.length; col++) {
if (matrix[row][col] === num) {
return true
}
}
return false
}
function usedInCol(matrix, col, num) {
for (let row = 0; row < matrix.length; row++) {
if (matrix[row][col] === num) {
return true
}
}
return false
}
function usedInBox(matrix, boxStartRow, boxStartCol, num) {
for (let row = 0; row < 3; row++) {
for (let col = 0; col < 3; col++) {
if (matrix[row + boxStartRow][col + boxStartCol] === num) {
return true
}
}
}
return false
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
